
블로그 릴레이 - 사용 목적에 따른 Amazon S3의 클래스 정하기

안녕하세요 클래스메소드의 수재입니다.
본 블로그는 당사의 한국어 블로그 릴레이의 세 번째 블로그입니다.
이번 블로그의 주제는「사용 목적에 따른 Amazon S3의 클래스 정하기」입니다.
클라우드 스토리지로 S3를 활용할 때 모든 파일을 Standard 클래스의 S3에 저장할 수도 있지만 사용 용도에 맞게 클래스를 활용한다면 더욱 효율적으로 이용할 수 있습니다.
이번 글에서는 사용 목적에 따라서 적절한 클래스가 무엇인지 알아보고 각 클래스 이용에 대한 주의 사항을 알아봅니다.
S3 클래스의 종류
S3에는 다음과 같은 클래스가 있습니다.
- 범용
- S3 Standard
- S3 Standard-Infrequent Access(S3 Standard-IA)
- S3 One Zone-Infrequent Access(S3 One Zone-IA)
- S3 Intelligent-Tiering(S3 Intelligent-Tiering)
- S3 Express One Zone
- 아카이브(Glacier)
- S3 Glacier Instant Retrieval
- S3 Glacier Flexible Retrieval(구 S3 Glacier)
- S3 Glacier Deep Archive
이 외에 온프레미스 AWS Outposts 환경에 사용하는 S3로 S3 Outposts 도 있습니다.[1]
S3 Standard
가장 많이 사용하게 되는 범용적인 클래스이며 특별한 지정을 하지 않으면 보통 이 클래스에 먼저 파일이 저장됩니다.
그리고 자주 액세스 되는 데이터를 보존할 때 사용하게 됩니다.
사용 사례로는 동적 웹 사이트의 배포, 콘텐츠 배포, 모바일 및 게임 애플리케이션, 빅 데이터 분석 등이 있습니다.
S3 Standard-Infrequent Access(S3 Standard-IA)
S3 Standard의 내구성과 처리량을 보다 저렴한 요금으로 이용할 수 있는 클래스입니다.
다만 S3 Standard와 다르게 자주 액세스하지 않지만 필요할 때는 바로 액세스 할 수 있는 데이터에 적합합니다.
사용 사례로는 자주 액세스하지 않는 대신 장기간 보관이 필요한 파일의 저장이나 백업용 데이터 스토어 등이 있습니다.
S3 One Zone-Infrequent Access(S3 One Zone-IA)
S3 Standard-IA와 특성이 거의 같지만 최소 3개의 가용 영역에 저장하는 것과 달리 S3 One Zone-IA는 하나의 가용 영역에 데이터를 저장합니다.
가용 영역이 줄어들어 스토리지의 가용성이나 복원력이 줄어들지만[2] S3 Standard-IA에 비해 비용이 20% 정도 저렴합니다.
사용 사례로는 S3 Standard-IA와 유사하지만, 가용성이 조금 줄어들어도 문제가 없는 백업 데이터 등을 저장할 때 적합합니다.
S3 Intelligent-Tiering(S3 Intelligent-Tiering)
액세스 빈도를 예측할 수 없는 데이터를 보존할 때 고려하게 되는 클래스입니다.
이 클래스는 액세스 빈도에 따라 가장 비용 효율적인 액세스 티어로 데이터를 자동으로 이동합니다.
S3 Intelligent-Tiering은 3개의 티어를 가지고 있으며 빈도에 따라 각기 다른 티어로 데이터를 이동합니다.
액세스 빈도가 낮은 데이터를 저장하는 티어일수록 데이터 저장 비용이 저렴해집니다.
주요 사례를 나누기는 힘들며 처음 설명처럼 액세스 빈도를 예측할 수 없다면 고려해 볼 만한 클래스입니다.
S3 Express One Zone[3]
가장 자주 액세스하고 최소한의 지연 시간이 필요한 경우 고려하는 클래스입니다.
S3 Express One Zone은 S3 Standard에 비해 데이터 액세스 속도가 10배 빠르고 요청 비용을 50% 절감할 수 있습니다.
가용 영역은 하나만 지정할 수 있으며 보통 서버 리소스와 동일한 가용 영역을 지정하여 워크로드를 빠르게 실행할 수 있습니다.
사용 사례로는 SageMaker 모델 훈련, Athena, EMR, Glue 등의 서비스와 연계되는 경우가 많습니다.
S3 Glacier Flexible Retrieval(구 S3 Glacier)
연간 1~2회 액세스하고 비동기식으로 검색되는 데이터를 아카이브 하거나 대규모 데이터 집합을 무료로 검색할 수 있는 아카이브가 필요할 때 고려됩니다.
흔히 Glacier라고 하면 이쪽인 경우가 많습니다.
위에서 설명한 S3 기준의 클래스들은 대부분 바로 파일을 다운로드 할 수 있지만 Glacier 타입의 클래스는 복원이라는 과정 후에 다운로드 할 수 있습니다.
복원할 때 소요되는 시간은 클래스 및 복원 옵션에 따라 달라지며 최대 12시간이 걸리는 경우도 있습니다.
또한 복원 후 다운로드 할 수 있는 기간도 복원 옵션에 따라 달라집니다.
사용 사례로는 비용 걱정 없이 가끔 몇 분 안에 대규모 데이터 집합을 검색해야 하는 백업 및 재해 복구 등 가끔 검색하는 대량의 데이터를 검색할 필요가 있는 데이터에 사용하는 경우가 많습니다.
S3 Glacier Instant Retrieval
S3 Glacier Flexible Retrieval보다는 액세스가 빈번하지만, 즉각적인 액세스가 필요한 장기 데이터의 아카이브가 필요한 경우 고려됩니다.
Glacier 클래스인데도 다른 클래스와 다르게 복원 작업 없이 파일 액세스가 가능합니다
(S3 Standard-IA) 스토리지 클래스를 사용할 때와 비교하면 최대 68%의 스토리지 비용을 절감할 수 있습니다.[4]
사용 사례로는 의료 이미지, 뉴스 미디어 자산 또는 사용자 생성 콘텐츠 아카이브와 같이 즉각적인 액세스가 필요한 아카이브 데이터에 많이 사용됩니다.
S3 Glacier Deep Archive
S3에서 가장 저렴한 스토리지 클래스이며 1년에 1~2회 액세스하는 데이터의 장기 보관이 필요할 때 고려됩니다.
S3 Glacier Flexible Retrieval는 옵션에 따라 복원을 3~5분 안에 완료하는 것도 가능하지만 이 클래스의 경우에는 대용량 데이터의 복원인 경우 최대 48시간이 소요될 수 있습니다.
하지만 스토리지 비용이 가장 저렴하기 때문에 복원에 시간이 걸려도 상관없는 장기간 아카이브 데이터에 적합합니다.
사용 사례로는 규정에 따라 장기간(7~10년)의 아카이브가 필요하거나 백업 및 장애 대책으로 사용되는 경우가 많습니다.
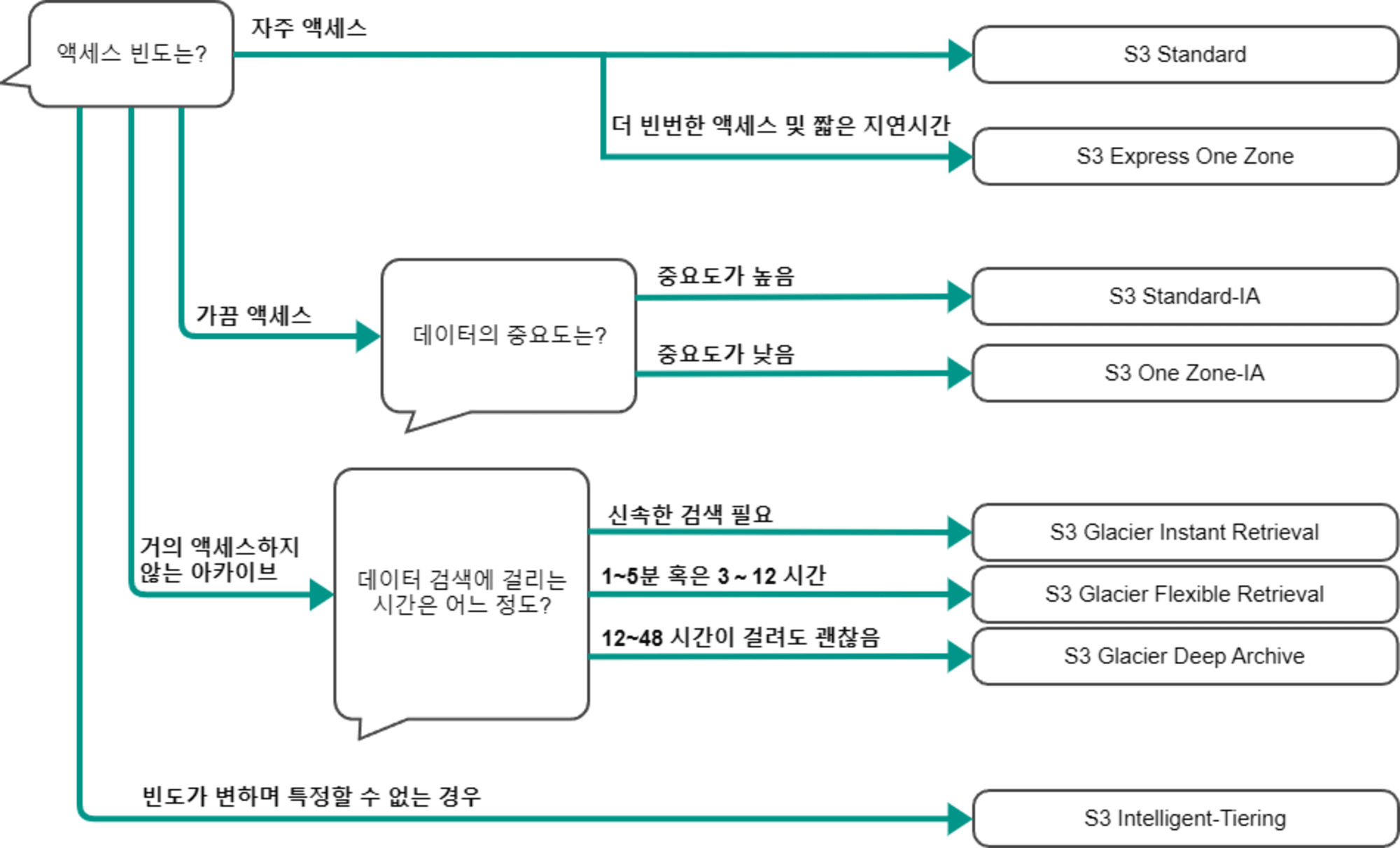
기준을 정리하자면
특성에 따른 기준을 정리하자면 다음과 같습니다.(확대가 필요하다면 이미지를 새 탭으로 열어주세요)
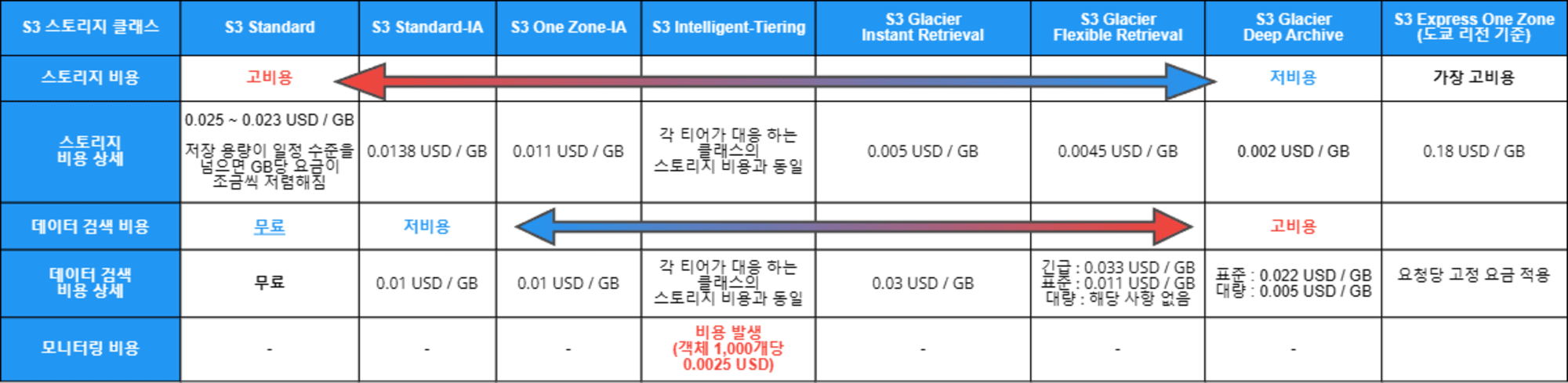
요금
스토리지 비용과 데이터 검색 비용을 정리하면 다음과 같습니다.
요금 책정에 대한 주의점
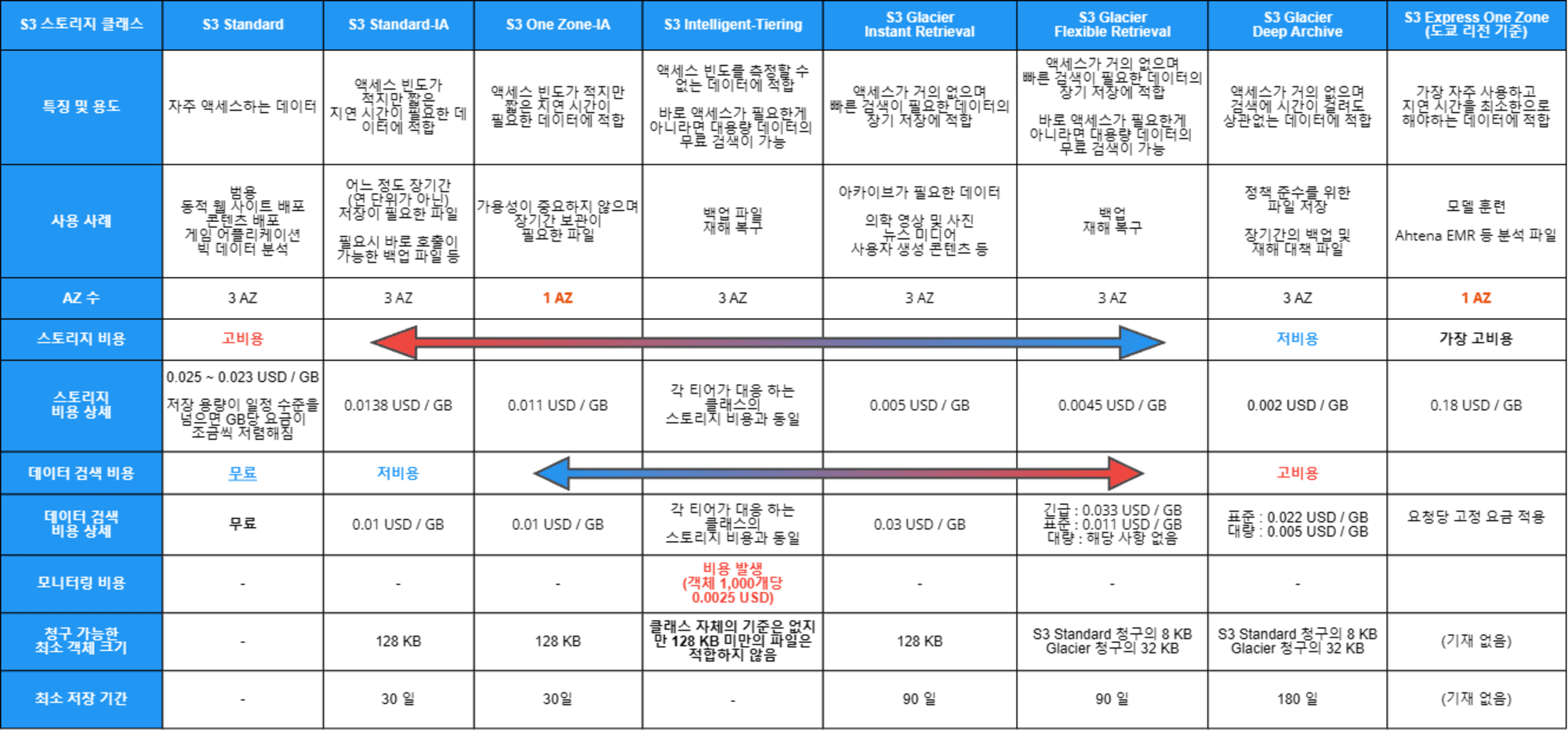
S3 Standard를 제외한 대부분의 클래스는 청구 가능한 최소 크기나 최소 저장 기간 등이 정해져 있습니다.
S3 Standard-IA 및 S3 One Zone-IA 도 마찬가지로 최소 객체 크기는 128KB입니다.
또한 30일 이라는 최소 스토리지 기간도 정해져 있습니다. 만약 30일보다 짧은 기간 저장하더라도 30일 저장한 금액이 청구됩니다.
S3 Glacier Flexible Retrieval 또는 S3 Glacier Deep Archive에 저장된 각 객체에 대해 8KB는 S3 Standard 요금이 부과되고, 32KB는 S3 Glacier Flexible Retrieval 또는 S3 Deep Archive 요금이 부과됩니다. 청구 가능한 최소 객체 크기는 없습니다.
S3 Glacier Instant Retrieval 클래스는 청구 가능한 최소 객체 크기는 128KB로 정해져 있습니다.
S3 Glacier Instant Retrieval 및 S3 Glacier Flexible Retrieval로 아카이브 된 객체는 최소 90일의 스토리지 기간 요금이 청구되며 S3 Glacier Deep Archive는 180일 입니다.
우선 S3 Intelligent-Tiering는 자동 계층화의 최소 적격 객체 크기는 128KB입니다. 보다 작은 객체는 모니터링하지 않으며 모니터링 및 자동화 요금 없이 항상 Frequent Access 티어 요금이 부과됩니다.
Archive Access, Deep Archive Access 티어에 아카이브 된 각 객체의 경우 Glacire 타입 클래스와 같이 메타데이터가 추가로 생성됩니다.
따라서 "액세스가 빈번하며 객체의 크기가 128KB보다 작은 파일" 의 경우에는 S3 Standard를 이용하는게 더 비용이 저렴한 경우가 있습니다.
혹은 몇 개의 파일을 128KB보다 큰 하나의 오브젝트로 만드는 전처리를 한 후 저장하는 것도 고려해볼 수 있습니다.
"액세스가 간혹 필요하지만 40KB보다 작은 파일" 도 단순히 Glacire 클래스에 저장한다면 파일의 크기보다 필요한 메타 데이터가 큰 상황이 되므로 byte 단위의 파일이라면 S3 Standard에 저장하거나 전처리를 한 뒤 Glacire에 저장하는 방법을 고려해 볼 수 있습니다.
정리하자면
위의 내용들을 정리하면 다음과 같습니다.(확대가 필요하다면 이미지를 새 탭으로 열어주세요)
수명 주기(라이프 사이클) 설정하기
S3에 저장된 오브젝트(파일) 시간에 따라 클래스를 바꾸도록 라이프 사이클을 설정할 수 있습니다.
S3 수명 주기 규칙 설정 (Lifecycle)([ 하면 잘하는 놈 ] Cloud Tech Blog)
마무리
한국어 블로그 릴레이의 세 번째 블로그「사용 목적에 따른 Amazon S3의 클래스 정하기」편이었습니다.
다음 네 번째 블로그 릴레이는 "Amazon Bedrock 사용해 보기" 이며 7월 둘째 주에 공개됩니다!
끝까지 읽어주셔서 감사합니다! AWS 사업 본부 이수재였습니다.



